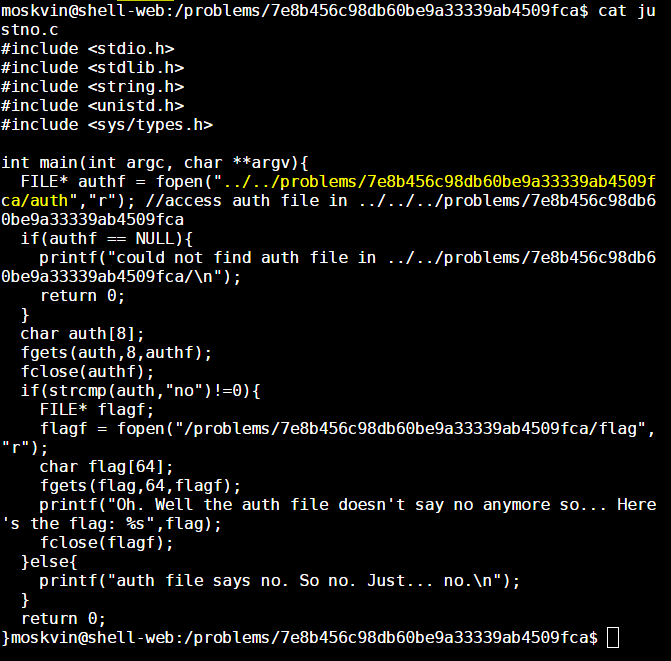
Open Source Intelligence (OSINT), or more precisely, the use of open source intelligence sources to profile the internet exposure of organisations (i.e. footprinting), is one of my favorite areas in information security particularly because it’s more or less of an open-ended problem at the moment.
There are a lot of interesting things that you can do with stuff that you can find in the open. For example, if you can manage to get your hands on a list of IP blocks that belong to an organisation that you’re doing a penetration test for, you can do a sweep on it and check for live hosts. Another example is, if you can manage to get your hands on a list of email addresses that belong to an organisation, you can iterate over it and cross-check each email address with a service such as HaveIBeenPwned in order to find various accounts belonging to your target organisation’s personnel that might have been compromised before.
A thing to note about open source intelligence is that it’s not just a practice for asset discovery and neither is it a practice that’s restricted to information security altogether. I’d personally describe it as a practice of collecting publicly available information from various sources, and analyzing the collected information in order to create a model which can be used to make decisions. Businesses and investors also make use of open source intelligence in order to perform competitive and market analysis among other things.
Table of Contents
- OSINT and Information Security
- Existing Footprinting Solutions
- Inquisitor
- Difference From Other Solutions
- Goals of Inquisitor
- Footprinting Concepts
- Types of Assets
- Inquisitor Workflow
- Limitations
- Future Developments
OSINT and Information Security
In the context of information security, open source intelligence can either be used offensively or defensively.
Defensive Use: Threat Forecasting
I would say that a potential defensive application of OSINT is threat forecasting. You might be able to do this by monitoring chatter on various online platforms and checking for red flags in order to forecast potential threats against your organisation. For example, you can monitor PasteBin for password leaks that might put your organisation at risk.
You’re probably going to need to do some pretty advanced stuff involving machine learning and natural language processing if you plan on automating this practice because you’re inevitably going to have to sort through a lot of unstructured information when dealing with chatter expressed in human language.
If I’m going to build an automatic threat forecasting system, I’d probably gather some information on what constitutes a red flag first and then determine what sort of metrics I can extract from that so that I’d have something to feed into a machine learning algorithm later on.
Perhaps I can gather a bunch of Facebook and Twitter posts threatening my organization and then create a bag-of-words or an n-gram model from them which I can then use to train a Naive-Bayes classifier to detect other posts that threaten my organization. This is similar to how spam filters work by the way.
Once I feed my metrics into a machine learning algorithm, it will produce a classifier, which, in turn, will allow me to automatically determine red flags in the future. Of course, this classifier will not be completely accurate and will have to be corrected with additional data as the system becomes more mature.
Alternatively, you can go for a sort of emphatic scoring system. In this approach, you try to determine how threatening a message is based on the words that it contains.
Let’s say you’re a cereal manufacturer and there’s some online chatter about you containing the words “exploit” or “vulnerability” or “leak” or some other technical words that don’t blend well with breakfast-related products. If you see something like that, that might indicate some sort of cyber threat against your organisation.
Offensive Use: Footprinting
As for potential offensive applications of OSINT: you can use it for footprinting as I earlier discussed in the opening paragraph of the article.
This is useful when you’re in the reconnaissance phases of penetration testing as you can leverage on the information provided by footprinting when performing other reconnaissance tasks such as scanning and enumeration. For example, as described in the opening section of this article, you can subject IP address ranges that you find via footprinting to port scans in order to find live hosts in your target’s networks.
You’ll also find the results of footprinting to be pretty useful in other non-reconnaissance-related penetration testing tasks such as when conducting vulnerability scans and performing exploitation tasks. Footprinting essentially allows you to have a map of your target organization’s assets, hence, you get a pretty good idea where to start probing for vulnerabilities.
Existing Footprinting Solutions
While tools such as Maltego and recon-ng do exist, as far as I know, they don’t automatically determine whether assets belong to your target or not. You have to manually sift through the acquired assets and pick out which ones belong to your target and which ones do not.
If you’re doing a penetration test for a client and you accidentally attack the wrong server, there might be a chance that you end up behind bars or paying some really large fine. Either way, the results aren’t going to be pretty so picking out the correct targets for attack is pretty important.
Also, for some of the tools mentioned above, you may also need to manually invoke the transformation directive of each of the assets that you have discovered, hence, adding additional work onto the plate of their operators.
Inquisitor
This project is located at https://github.com/penafieljlm/inquisitor.
This is my personal take on the footprinting problem though it is heavily inspired from how other existing footprinting tools (Maltego and recon-ng) operate. This approach includes additional goals that aren’t usually covered by your typical everyday footprinting solution such as automatically determining whether or not a specific asset belongs to a penetration tester’s target organization.
I’m gonna go ahead and point out that not everything can be automatically classified and we’re still going to need some guidance from the operator to ensure that the assets and their classifications are accurate in the end, but our goal is to minimize the effort required of the operator and make it easy and efficient for them to accurately find and classify assets.
Difference From Other Solutions
Rather than simply encapsulating OSINT sources, tools, and transforms, Inquisitor encapsulates an entire footprinting approach altogether. It’s an opinionated tool. It has opinions on what sort of semantics each asset type follows, how certain asset types are to be transformed, what the logical relationships between asset types are, how each asset type is identified, what attributes about an asset should be recorded, how assets should inherit classification labels from other assets, among other things.
Inquisitor is also an organization-centric tool. It’s not a general reconnaissance tool like recon-ng or Maltego. It revolves around the goal of profiling the internet exposure of organizations and not individual users or some other entity types, so expect that the “opinions” built into Inquisitor were considered under that context.
Finally, Inquisitor also seeks to determine which assets actually belong to the target organisation. This will be discussed in more detail below.
Goals of Inquisitor
The main goal of Inquisitor is to easily and accurately profile the internet exposure of target organisations. That means we want little if not zero false positives from our results (false negatives are fine). We want to avoid attacking the wrong assets later on when we get to the other steps of penetration testing. This is especially useful when you’re trying to automate vulnerability assessments for an entire organisation from the outside.
In order to achieve the main goal, I layout the following sub-goals for Inquisitor:
Automatic Asset Classification
As much as possible, if an asset can automatically be classified with one-hundred percent certainty, it should be done.
For example, if the registrant name of a domain has been manually classified as belonging to the target organisation, then the domain’s ownership classification should inherit that. If the registrant name has not been manually classified, then we can defer to inheriting the classifications of its parent domains.
The example above only applies for domain name assets though. A different asset type would require a completely different classification inheritance logic. As mentioned previously, Inquisitor is an opinionated tool and opinionated approaches to asset classification inheritance have also been built into it.
Easy Manual Inspection and Classification of Assets
In cases where we are not able to automatically classify assets, we should be able to easily determine the non-classified assets that are likely to belong to the target organisation by using some sort of heuristic approach. A possible approach would be to quantify how similar a specific asset’s attributes are to the attributes of the assets that are known to belong to the target organisation and then ordering the non-classified assets from most likely to belong to the target organisation to least likely to belong to the target organisation before being presented to the user for manual classification.
The logic to quantify an asset’s divergence from the target organisation’s known owned assets is going to depend on what type of asset is being handled, and in the context of Inquisitor, it’s going to be implemented in an opinionated form as well.
Automatic and Appropriate Asset Transformation
Of course, as with any reconnaissance tool, we’d want to be able to apply the appropriate kind of transformation logic to every asset type that we want to handle and we would want to be able to do this automatically for assets that are known to be owned by the target organisation.
The transformation logic, would, of course, vary between the different types of assets that we want to handle. For example, you can’t transform an IP Block the same way that you would transform a domain name because the semantics surrounding them are different. Let’s take for example the transformation directive “retrieve the subdomains of a domain”. One of the approaches that you could take to implement this directive is to go on Google and enter host:coca-cola.com. That sort of transformation directive will not work on, say, an IP Block because the query host:52.0.0.011 simply does not make sense. An IP block has to be handled under its own semantics and so does every other asset type.
Non-Use of Enumeration Techniques
Lastly, since Inquisitor is a footprinting tool (i.e. it attempts to find target assets in a non-“intrusive” way), we want to avoid employing exhaustive enumeration techniques on our target’s assets.
Sure, we might get more thorough results if we do a complete sweep of our target’s IP ranges, but chances are, our attempts to probe their network will not go unnoticed. One of the reasons that we’re using open sources is to keep our target from knowing about our reconnaissance maneuvers, so that’s why we would want to avoid hammering them with probe requests.
Other than that, enumeration techniques typically fall under the scope of the scanning phase of penetration testing, so it’s really not our concern here, but note that footprinting and scanning go hand-in-hand when profiling the entire internet-facing infrastructure of an organization.
Footprinting Concepts
Now that the goals for Inquisitor have been defined, let’s go over some basic footprinting concepts that you need to know in order to understand how Inquisitor works.
Seeding
Before Inquisitor starts looking for the assets of our target organisation, we first need to give it some information that we already know about our target. Inquisitor can’t just characterize organisations without any information to start off from, so we’re going to have to give it some hints before it starts running. If we don’t seed Inquisitor, we’re not going to get anywhere.
Anyway, the process of “seeding” can basically be described as enumerating “facts” that we know about our target prior to conducting transforms. In the context of Inquisitor, facts include, “the target organisation registers some of its assets under the name The Coca-Cola Company” or “the target’s primary website is coca-cola.com” or “the network 208.53.200.104/29 belongs to our target organisation”.
I believe the concept of seeding is pretty much the same when using Maltego or recon-ng minus the asset classification label portion of the initial information provided to the tool.
Canonicalization
The process of canonicalization refers to expressing the various representations of a specific asset into a “standard” form which is also referred to as its “canonical form”.
For example, in the case of discovering domains names of a target organisation, we might acquire two domain names represented as ᴡᴡᴡ.Coca-Cola.com and ᴡᴡᴡ.coca-cola.com. It’s pretty obvious that these two domain names refer to the same domain, but when you compare them using an equality operator, the results will indicate that they are not the same because one has uppercase letters and the other does not. This is where canonicalization comes in. If we canonicalize both the ᴡᴡᴡ.Coca-Cola.com and ᴡᴡᴡ.coca-cola.com domains, we’ll end up with the ᴡᴡᴡ.coca-cola.com and ᴡᴡᴡ.coca-cola.com domain names respectively. When both domain names are expressed like this, equality operators will have no problem determining that these two domains are one and the same.
This works only for the domain name asset type however. Different asset types will demand a different canonicalization method depending on the semantics surrounding them.
Transforms
The process of performing transforms can basically be described as looking up information that we have yet to know about the target based on the information that we already know about the target.
If we know that the domain coca-cola.com belongs to our target, then we can perform a bunch of operations which will help us enumerate more assets that might belong to our target based on that fact.
For example, we can perform a site:coca-cola.com query on Google which will give us a list of domain names under coca-cola.com such as dunkinanytime.coca-cola.com. Note that in order to perform this query, we needed to know that coca-cola.com belonged to our target first.
Inference
The process of inference simply involves inferring the existence of other assets based on the fact that a specific asset and its metadata exists. Inference requires no additional lookup to be performed, and instead, other assets are directly derived from an asset and the metadata attached to it (such as whois information).
For example, if we know that ns1.coca-cola.com exists, we can infer that its parent domain coca-cola.com exists without performing any sort of lookup whatsoever. Another example would be, if the email admin@coca-cola.com exists, then we can directly infer that the coca-cola.com domain exists.
Like transforms, the process of inference depend heavily on the semantics of the asset type being subjected to the inference process.
Classification
The classification process is where we determine whether or not an asset belongs to our target organisation.
There are three classification labels: accepted, rejected, and unclassified.
The accepted classification label indicates that an asset is owned by the target organization. The rejected classification label indicates that an asset is not owned by the target organization. The unclassified classification label indicates that an asset hasn’t been classified as either accepted or rejected yet.
The classification process depends heavily on the semantics surrounding the asset type being subjected to classification especially if automatic classification is being attempted.
In Inquisitor, assets may be classified automatically, manually, or via a rule. Manual classifications take precedence over rules-based classifications, and rules based classifications take precedence over automatic classifications.
Automatic Classification
In Inquisitor, automatic asset classification operates by inheriting the classifications of related assets. As stated previously, this process depends heavily on the semantics surrounding the asset type being subjected to classification.
For example, a domain can automatically classify itself based on the classification of its parent domain or its registrant name – that is, if either the registrant name The Coca-Cola Company or the domain name coca-cola.com is owned by our target organisation, then we know that ns1.coca-cola.com is also owned by our target organisation.
Naturally this process differs between different asset types. For example, email addresses don’t have registrant names and must defer to the ownership classification of their domains.
Manual Classification
If an asset cannot be automatically classified or if an incorrect classification was made, then the user can manually classify or re-classify it.
The manual assignment of an asset to a specific classification takes precedence over all other classification methods. That means that if the domain coca-cola.wordpress.com was manually classified as accepted, it will always be classified as accepted even if its registrant name or parent domain were classified as rejected, and even if a rule rejecting domains matching *.wordpress.com is present.
Assets with manual classifications actually serve as starting points for the whole classification inheritance process described above. The whole concept of the seeding process is actually based upon manually introducing and classifying assets that aren’t recorded on the intelligence database yet.
The more assets that you manually classify, the better the coverage and accuracy of your results will be since the system has more “facts” to infer conclusions from. It’s sort of like machine learning in a sense.
Rule-Based Classification
Rule-based classification allows for the definition of accept/reject rules that assets matching a specific criteria will inherit. For example, one can declare that all domains under amazon.com be automatically rejected via the rule reject domain.name~=.*\.amazon\.com.
Just imagine an access control list, but for Inquisitor assets.
Acceptability
The process of determining asset acceptability aids the process of manual classification by allowing potentially owned assets to be sorted according to their similarity with assets that are known to belong to the target, thus allowing assets that are most likely to belong to the target to be evaluated and manually classified first.
Like some of the concepts introduced above, the process of determining the acceptability rating of an asset heavily depends on the semantics of the asset type being subjected to acceptability rating quantification.
For example, one of the approaches that can be taken to quantify the acceptability rating of a certain domain name is to check if its zones contain substrings that are common among domains that have been classified as accepted. If many domains that have been classified as accepted contains an elevated instance of the substrings coca and cola, and the domain we’re evaluating contains those two words, then that should raise the acceptability rating of the domain that we are currently assessing.
Parental Relationships
For the purpose of visualising the assets that were found during OSINT analysis, it is required that assets have the ability to know which other asset best serves as their “parent”.
The process of determining which parent asset a specific asset belongs to is entirely dependent on the semantics surrounding the asset in question.
For example, domain names and network blocks can be registered under a specific registrant name, making that registrant name effectively the “parent” of those two assets. A host can also exist under another domain name such as in the case of ᴡᴡᴡ.coca-cola.com and coca-cola.com, etc. If a specific asset has no parent, such as in the cases of registrant names, they directly fall under the target organisation itself.
Types of Assets
While there maybe countless types of assets that can potentially be subjected to OSINT discovery, the initial scope of Inquisitor includes only the most common “internet objects” for now. These include internet objects such as registrant names, network blocks, domain names, email addresses, and social media accounts. Each will be discussed individually below.
Registrant Names
Registrant names are the names that organisations use to register their assets to various registries and authorities.
For example, when reserving a network block on an internet registry such as ARIN, an organisation may use names such as The Coca-Cola Company in their request for a network block. Once the request is approved, ARIN binds that registrant name to the network block that has been allocated to the organisation in question.
Organisations tend to use the same registrant names when registering for other things such as domain names and X.509 certificates, so it’s a pretty useful determinant of asset ownership. Additionally, the authorities which manage network blocks, domain names, and X.509 certificates also verify the entities behind registrations thus allowing us to have more confidence in the authenticity of the relationship between an asset and a registrant name.
Canonicalization
To canonicalize registrant names:
- Strip leading and trailing spaces
- Remove extra spaces between words
- Perform unicode transliteration
- Convert to uppercase
A canonicalised registrant name should look something like THE COCA-COLA COMPANY.
Inference
There are no assets that you can infer from the registrant name alone.
Transforms
To discover assets related to a registrant name:
- Internet Registry Transform
- Sources
- ARIN
- RIPE-NCC
- APNIC
- LACNIC
- AFRINIC
- Inputs
- Registrant Name
- Outputs
- Registrant Names
- Network Blocks
- Email Addresses
- Sources
- Google Transform
- Sources
- Inputs
[registrant-name]site:facebook.com [registrant-name]site:linkedin.com [registrant-name]site:twitter.com [registrant-name]site:instagram.com [registrant-name]site:github.com [registrant-name]
- Outputs
- Domain Names
- Email Addresses
- Social Media Accounts
- Sources
- Shodan Transform
- Sources
- Shodan
- Inputs
[registrant-name]org:"[registrant-name]"
- Outputs
- Registrant Names
- Domain Names
- Sources
Classification
If the registrant name has not been manually classified as belonging to the target organisation, then it does not. Registrant names have no means of inheriting classification labels from other assets.
Parent
Registrant names are top-level objects and they directly fall under the target organisation.
Acceptability
The computation of the acceptability rating of an unclassified registrant name involves removing all unicode transliterated NLTK stopwords from the registrant names to be compared and then calculating the maximum Needleman–Wunsch similarity score between all accepted registrant names and the unclassified registrant name being rated.
This GitHub project provides a good implementation of the Needleman–Wunsch algorithm. The best part about it is that it outputs an identity score that we can use directly.
Here’s a sample of the algorithm in action:
>>> alignment.needle('COCA-COLA COMPANY', 'COCA-COLA HELLENIC BOTTLING COMPANY')
Identity = 48.571 percent
Score = 80
COCA-COLA------------------ COMPANY
COCA-COLA COMPANY
COCA-COLA HELLENIC BOTTLING COMPANY
>>> alignment.needle('COCA-COLA COMPANY', 'PEPSICO, INC')
Identity = 23.529 percent
Score = -25
COCA-COLA COMPANY
CO N
PEPSICO-, ----INC
>>>
Post-Footprinting
Registrant names don’t really have a use outside of footprinting or scanning.
Network Blocks
Network blocks are essentially ranges of IP addresses that are reserved by an internet registry for the use of a specific organisation. These IP blocks can serve as targets for scanning in subsequent phases of penetration testing.
Note that not all hosts under an IP block are automatically owned by the organisation owning the IP block. Some organisations decide to delegate some sub-ranges of their blocks to other organisations, hence, it’s possible that some hosts under an IP block may be out of scope for your penetration testing project. Usually, in these cases, the registrant name of the most immediate IP block parent of an IP address can be checked to determine whether the IP address in question does indeed belong to your target organisation or not.
There’s another thing that needs to be noted when it comes to ownership of IP addresses especially when it comes to PaaS and IaaS providers, and that is: the fact that an organisation owns an IP address does not immediately mean that it owns the services running on that IP address.
Take for example, Amazon Web Services (an IaaS provider). While you can rent out one of their machines to host your organisation’s business applications, the IP that will be allocated to the machine that you’re renting will still fall under Amazon’s IP address range. Technically the IP address belongs to Amazon, but clearly, the service that’s running on it belongs to you. You need to keep this in mind if you wanna avoid unintentionally going out of scope during penetration testing. However, you won’t usually encounter this problem unless the organisation that you’re doing footprinting for offers a service delegating its IT resources to third parties (such as Amazon).
Whois information should be attached to a network block object upon initialisation.
Canonicalization
Network blocks should be expressed in CIDR format. If you’re implementing canonicalization in code, you’d probably be better off using some third party package which parses CIDR strings such as the netaddr package in Python.
A canonicalized network block should look something like 52.0.0.0/11.
Inference
From the whois information attached to the network block object upon initialization, we may be able to infer the following:
- Registrant Name
- Network Blocks
- Parent Network Blocks
- Child Network Blocks
- Email Addresses
- Administrative Contact
- Abuse Contact
- Tech Contact
Transforms
To discover assets related to a network block:
- Shodan Transform
- Sources
- Shodan
- Inputs
net:[network-block]
- Outputs
- Registrant Names
- Domain Names
- Sources
Classification
If the network block has not been manually classified as belonging to the target organisation, then it defers to the classification label of the registrant name associated with it.
We don’t inherit the classification labels of parent network blocks because that allows for false positives to seep into the classification inheritance process. For example, if your target organisation delegates network blocks to other organisations (e.g. Verisign), then everyone you delegate network blocks to will inherit the classification label of the “master” network block that you’re dividing for everyone. That will be very bad especially if you’re planning to do scanning and enumeration later on since you’re treating all networks blocks under the “master” network block as if they were owned by your target organisation, when in fact, they’re not.
Additionally, the whole point of having subnetworks is to have the ability to delegate the administration and/or ownership of a portion of a network to another entity, hence, inheriting the classification label of parent network blocks simply makes no sense. Although, the practice of dividing network blocks into smaller network blocks for the same organization exists, such practice occurs primarily within the context of private IP address spaces.
Parent
A network block can fall under other larger network blocks that are owned by the target. The smallest other target-owned network block that is able to contain the network block in question becomes its immediate parent. If no other network blocks can contain the network block in question, then the target-owned registrant name associated with it becomes its parent. If no registrant name is available, it becomes a top-level object.
Acceptability
There is no known method to determine the acceptability rating of a network block so far, but you won’t be manually classifying network blocks anyway as I will discuss later on, so I don’t think it will be that big of a deal.
Post-Footprinting
The use of network blocks beyond footprinting mostly revolve around subjecting them to various scanning techniques in order to discover new assets that footprinting was not able to find.
Ping Sweeps, Port Scans, Version Scans, and Vulnerability Assessments
You can perform port scans and ping sweeps of entire network blocks in order to find live hosts and services.
Upon finding live services, you may subject them to version scanning which detects vulnerable versions of network services off the bat. You’d want to leverage these vulnerable network services later on once you reach the penetration testing step where you try to actually break into the target’s internal corporate network.
You may also want to subject detected web applications to further testing. This would include testing for vulnerable versions of the web server being used, vulnerable versions of SSL, vulnerable versions of the Content Management System being used, vulnerable versions of the framework being used, and other common web application vulnerabilities (see the OWASP Top 10 project).
Domain Names
Domain Names are essentially strings defining a zone of administrative authority. By this, we mean that every name that falls under a specific domain name is administered by the organisation owning the domain name in question. These names include subdomains and hostnames (i.e. domain names that translate to IP addresses).
The collection of domain names that one would end up with after the footprinting process can serve as starting points for scanning and enumeration when one arrives in the subsequent phases of penetration testing.
Whois information should be attached to a domain name object upon initialization. An attempt should also be made to authoritatively resolve the domain name to an IP address, and if successful, the corresponding IP whois information and chain of DNS servers involved in the resolution should be attached to the domain name object. Lastly, if a domain name is successfully resolved into an IP address, a quick attempt should be made to see if a TLS/SSL service exists on that address, and if one does exist, the TLS/SSL certificate should be attached to the initialized domain name object as well.
Canonicalization
To canonicalize domain names:
- Strip leading and trailing spaces
- Convert to lower case
The verification of the entire domain name and each zone string should also be performed. Zones can pretty much be described as the “nodes” of a domain name. For example, in the case of the domain name ᴡᴡᴡ.coca-cola.com, its zones would be ᴡᴡᴡ, coca-cola, and com.
Valid zone names typically comply with the following rules:
- Must not contain spaces
- Must not start with a dash
- Must be between 1 to 63 characters
Meanwhile, valid domains names typically comply with the following rules:
- All zone names are valid
- Must not exceed 253 characters
- The top-level domain (i.e. the right most zone, such as
com,net,org, etc.) must be in the list of valid top-level domains
This verification process prevents IP addresses and other invalid values from being treated as domain names. This is important because sometimes various assets are scraped off unstructured documents.
Inference
From the two pieces of whois information attached to the domain name object upon initialisation, we may be able to infer the following:
- Registrant Names
- Whois Information
- Registrant Organization
- Admin Organization
- Tech Organization
- TLS/SSL Certificate
- Subject Organization
- Whois Information
- Domain Names
- Parent Domain Name
- Whois Name Servers
- DNS Resolution Name Servers
- TLS/SSL Certificate Subject Common Name
- Email Addresses
- Whois
- Registrant Email
- Admin Email
- Tech Email
- Whois
- Network Blocks
- Network Block of corresponding IP address
Transforms
To discover assets related to a domain name:
- Google Transform
- Sources
- Inputs
site:[domain-name]"@[domain-name]"
- Outputs
- Domain Names
- Email Addresses
- Social Media Accounts
- Sources
- Shodan Transform
- Sources
- Shodan
- Inputs
hostname:[domain-name]
- Outputs
- Registrant Names
- Domain Names
- Sources
Classification
The classification inheritance mechanism of domain name objects is probably the most complicated out of all asset types. As such, I will be breaking the process down into subsections in order to make it more understandable.
Manual Classification
If the domain name object has been manually classified by the user, it inherits the classification label that the user has assigned to it and then stops immediately.
Whois Registrant Name
If a registrant name exists for a domain name and it has a definitive classification label (either “rejected” or “accepted”, and not “unclassified”), then the domain name inherits that classification label and stops immediately.
A domain’s registrant name can be found in the “registrant organization” attribute of the whois information attached to it.
This classification inheritance rule is great for sorting out “organization-level” domain names (i.e. those that are directly enrolled to domain name registrars such as coca-cola.com).
Parent Domain Name
If no registrant name exists for a domain name, or no definitive classification label exists for the registrant name associated with a domain name, then the classification inheritance process defers to the classification label of the domain name’s parent, if and only if, the parent is classified as “accepted”.
We add the condition indicated at the end because sometimes domains belonging to a different organization can contain domains that belong to the target organization. For example: the com domain belongs to Verisign, but the coca-cola.com domain belongs to the target. The fact that com is rejected should not imply that coca-cola.com is rejected as well. However, if a domain is accepted, it should imply that all of its subdomains are accepted. This assumption, however, does not work well with organizations that offer IaaS/PaaS services and domain name registrars such as Verisign because that would imply that all domain names under com is owned by Verisign. This is one of the limitations that I have identified with the Inquisitor approach, and I’ve included this note in the “limitations” section of this article.
At this point, you might be asking why we inherit classification labels of parent domain names but not parent network blocks.
The answer is simple: the point of having a hierarchical domain name system is to have the ability to hierarchically organize the network assets of organizations. The network assets that fall under a specific domain generally belongs to the most immediate organization owning that domain because that’s how domains are meant to work in the first place.
In the case of network blocks, public IP address ranges are typically divided so that they can be allocated to another organization, hence, it would make sense that the owner of a parent IP block would usually be an organization distinct from the owner of a child IP block. An organization’s network assets can be hierarchically organized too using network blocks though, but that usually happens within private IP address ranges.
This classification inheritance rule is great for sorting out “service-level” domain names (i.e. those that fall under organization-level domain names such as ᴡᴡᴡ.coca-cola.com or mail.coca-cola.com).
Authoritative Name Server
If the parent domain is not classified as accepted, we defer to the classification label of the authoritative name server that has resolved the domain name into an IP address, if and only if, the authoritative name server is classified as “accepted”.
This classification inheritance rule is great for sorting out organization-level domain names that do not fall under an accepted domain name, and aren’t properly registered with an appropriate registrant name or are registered with a registrant name that hasn’t been manually classified as “accepted” yet.
An example of this would be the coca-cola.com.br domain. Notice that it’s registered under the name RECOFARMA IND. DO AMAZONAS LTDA and it doesn’t fall under an accepted domain name, yet the authoritative DNS server that has resolved it is ns3.ko.com which is a DNS server owned by THE COCA-COLA COMPANY.
This inheritance rule will only work if a successful DNS resolution could be made though. It also doesn’t work well with organizations offering domain name registration and IaaS/PaaS services because such organizations occasionally own the authoritative DNS servers which resolve names owned by other entities, hence, introducing false positives in the classification inheritance process.
TLS/SSL Certificate Subject Organization
If the authoritative name server is not classified as accepted, we defer to the classification label of the subject organization name (which we will treat as a registrant name) indicated in the TLS/SSL certificate associated with the domain name, if and only if, the classification label in question is “accepted” and it is verified that the certificate is for the host that the domain name resolves to.
To verify if a provided certificate belongs to a domain, you check the DNS resolution chain for CNAMEs and compile all CNAMEs into a list and then add the original domain name to that, and then see if the certificate’s common name match any of the domains in the list.
This inheritance rule will only work if a TLS/SSL service is running on the host that a domain name resolves to.
Parent
A domain name can fall under other domain names that are owned by the target. Usually, inferring the parent of a domain name is as simple as removing its leftmost zone label (e.g. the parent of ᴡᴡᴡ.coca-cola.com is coca-cola.com). If the immediate parent of a domain name does not belong to the target however, it defers to the most immediate owned network block where its resolved IP falls under. If there’s no qualified network block or if the domain name cannot be translated into an IP address, then it falls under the registrant name associated with it given that the registrant name is owned by the target. If there is no qualified registrant name, then the domain name becomes a top-level object.
Acceptability
The computation of the acceptability rating of an unclassified domain name involves stripping off registry-level zone labels (e.g. com, co.uk, etc.) and then calculating the maximum Needleman–Wunsch similarity score between all accepted domain names and the unclassified domain name being rated.
Here’s a sample of the approach in action using the Needleman–Wunsch GitHub project we used earlier:
>>> alignment.needle('coca-cola', 'coca-colaproductfacts')
Identity = 42.857 percent
Score = 30
coca-col---------a---
coca-col a
coca-colaproductfacts
>>> alignment.needle('coca-cola', 'pepsico')
Identity = 22.222 percent
Score = -15
coca-cola
co
pepsico--
>>>
Post-Footprinting
Domain names may be subjected to further discovery efforts by employing various scanning techniques. These techniques go beyond the scope of footprinting and are therefore not included in Inquisitor’s function. Some of the scanning techniques that may be employed on domain names include two processes that I call Service Name Enumeration and Locality Enumeration.
After these scanning steps, domain names may also be subjected to port scans, version scans, and vulnerability assessments in order to find potential entry points into the target organization’s internal network.
Lastly, you can also search for password dumps containing emails under a certain domain name on sites like PasteBin.
Service Name Enumeration
Basically, this process involves detecting service names in a domain name and swapping that out with another service name and checking to see if we can resolve the resulting domain name into an IP address.
Let’s take for example that we have the following list of “service names” that we will be using for this process:
ftpsmtpmailᴡᴡᴡns1ns2
Now, our input for this example shall be the ᴡᴡᴡ.coca-cola.com domain.
Observe the domain name being evaluated. We can see that it contains a service name that is in our list, namely, ᴡᴡᴡ.
Now, as described in the process above, we replace this with the other service names in our list and attempt to resolve them into IP addresses.
ftp.coca-cola.com => [no-response]smtp.coca-cola.com => [no-response]mail.coca-cola.com => 94.245.120.86ns1.coca-cola.com => [no-response]ns2.coca-cola.com => [no-response]
And voila! We found a new host, which is mail.coca-cola.com.
Here’s a neat list of service names from Daniel Miessler’s SecLists project if you need a more comprehensive one.
Locality Enumeration
This process is essentially the same as service name enumeration except we attempt to find labels indicating a locality in domain names and then swap them out with other locality labels and then testing if they exist by resolving them into IP addresses.
Let’s take for example that we have the following list of “locality labels” that we will be using for this process:
cophnlchru
Now, our input for this example shall be the ᴡᴡᴡ.coca-cola.com.ph domain.
Observe the domain name being evaluated. We can see that it contains a locality label that is in our list, namely, ph.
Now, as described in the process above, we replace this with other locality labels in our list and attempt to resolve them into IP addresses.
ᴡᴡᴡ.coca-cola.com.co => 184.30.202.52ᴡᴡᴡ.coca-cola.com.nl => [no-response]ᴡᴡᴡ.coca-cola.com.ch => [no-response]ᴡᴡᴡ.coca-cola.com.ru => 194.85.61.76
And now we end up with a couple of new hosts: ᴡᴡᴡ.coca-cola.com.co and ᴡᴡᴡ.coca-cola.com.ru.
Here’s a list of of locality labels maintained by Mozilla. As you’ve noticed, “locality labels” do coincide with top-level domains and “registry-level” domains (we’ll discuss that later).
Email Addresses
Email addresses are basically used to identify subjects that can send or receive emails. They’re composed of an identifier and a domain name (i.e. identifier@domain.com). I think we’re all pretty familiar with how this works. Anyway, once you get further into the penetration testing process, you’ll basically want to take all of the email addresses that you have been able to gather and then perform a spear-phishing campaign on them as part of the “gaining access” part of penetration testing.
Canonicalization
To canonicalize email addresses:
- Strip leading and trailing spaces
- Lower-case the domain portion of the email address
The verification of the email address’ syntax should also be performed.
Inference
The only information that you can infer from an email address is its domain name.
Transforms
To discover assets related to an email address:
- Google Transform
- Sources
- Inputs
"[email-address]"
- Outputs
- Domain Names
- Email Addresses
- Social Media Accounts
- Sources
Classification
If the email address has not been manually classified as belonging to the target organization, then it defers to the classification label of the domain name associated with it.
Parent
An email address can only fall under a domain name owned by the target, preferably the most immediate one. If this condition cannot be satisfied then the email address becomes a top-level object.
Acceptability
Computing the acceptability rating of email address involves inheriting the acceptability rating of the domain name associated with it.
Post-Footprinting
The primary post-footprinting purpose of email addresses are to be phishing targets. Aside from that, they may also be used to check for compromised credentials. You can go to sites like HaveIBeenPwned to check if an email address has been compromised in a data breach. You can also search for password dumps that a certain email address has been part of on sites like PasteBin.
Social Media Accounts
Accounts from various social media websites such as Facebook, Twitter, and LinkedIn typically fall under the distinction of “social media account”. While, in implementation, different semantic rules, hence, different canonicalization, inference, transform, and classification techniques, would apply to different each type of social media accounts, there are too many of them for me to discuss, so I believe it would be more practical, for the sake of this article, if I generalize them in this section.
Upon initialization of a social media account object (whether it be for LinkedIn or whatever), it would be great if you can manage to scrape off some information about the account from the website or the social media service’s API (if they have one).
One useful method for extracting additional information about a social media account would be to use the Google Search API. It can provide you structured information about a social media account. In the case of LinkedIn, Google Search API can provide you a LinkedIn account’s organization name, role name, location, and other information that you can use in transforms and inferences later on.
Canonicalization
Given that each type of social media account follows its own unique semantics, different canonicalization rules would have to apply to each of them as well, but generally, you’d want to use anything unique about each account as their identifier. These unique account identifiers may either be usernames, GUIDs, account numbers, email addresses, etc., and they may follow some unique set of semantics such as being case-insensitive, having a specific length, following a certain regular expression, etc.
Generally, you’d want to take note of the following:
- What sort of data does the social media service use to identify accounts?
- Usernames?
- Globally Unique Identifiers?
- Account Numbers?
- Email Addresses?
- What sort of rules do the identifiers follow?
- Case-sensitivity rules?
- You should upper-case or lower-case the identifiers if this is the case
- Length rules?
- Regular expressions rules?
- Case-sensitivity rules?
Let’s take LinkedIn for example. LinkedIn uses case-insensitive usernames to identify users. In cases like these, you’d want to implement the following canonicalisation procedure:
- Strip leading and trailing spaces
- Convert to lower case
You’d also want to implement a verification mechanism during canonicalisation. It could be as simple as accessing the user’s account by visiting their profile at https://ᴡᴡᴡ.linkedin.com/in/, and verifying the response of the website. Some social media service websites might return a 404 or some unique message indicating that the account does not exist. In the case of LinkedIn, you’d be redirected to a specific URL https://ᴡᴡᴡ.linkedin.com/in/unavailable, so in this case, you’d want to watch out for a 302 with the redirect URL above.
Inference
As with canonicalization, different inference procedures will apply to different types of social media accounts as well. The assets that you would be able to retrieve in the inference process would depend on the information that you were able to scrape from the social media service’s website, API, or Google Search results.
Some of the possible things that you might have retrieved may include:
- Email addresses
- Hyperlinks
- Links to other social media accounts
- Organization names
As such, we may be able to infer the following information:
- Registrant Names
- Retrieved organization names
- Domain Names
- Retrieved hyperlinks
- Email Addresses
- Retrieved email addresses
- Social Media Accounts
- Retrieved links to other social media account
Transforms
If a social media object is identified by a username or has a username associated with it, it could be used as a transformation input since users generally tend to use the same username across different platforms, especially if they’re trying to cultivate an online presence. However, using GUIDs or account numbers as transformation inputs simply makes no sense as they’re not guaranteed to make sense outside the context of the service that they exist in.
Anyway, to discover assets related to social media accounts:
- Google Transform
- Source
- Inputs
"[social-media-account.username]"
- Outputs
- Domain Names
- Email Addresses
- Social Media Accounts
- Source
Classification
Automatic classification can be a really tricky business in the context of social media accounts because of how varied they are (or maybe it’s because I’m trying to generalize a really large and diverse set of object types here). However, there MAY be some cases where automatic classification can be performed.
Social media services such as LinkedIn associate accounts with specific organization names. In these cases, it may be appropriate to treat the organization name as a registrant name and inherit its classification label. The social media service should provide verification of the organization name however, so that not anybody can just claim that they’re organization X. This verification requirement is a given when it comes to internet registries so that’s why we can trust them, but social media does not necessarily verify its registered users and organizations, so we can’t trust them to give us an honest answer off the bat.
If a social media account has an email address associated with it and the service requires the completion of an email address validation procedure prior to allowing users to use the service, the social media account can inherit the classification label of the email address in question. There may be instances where social media accounts registered with email addresses belonging to the target organization are being used for personal use, but in cases such as these, I think it’s still fair game for penetration testers to conduct spear phishing on the owners of these accounts as they are probably associated with the target organization as well. I mean, how would you get a @coca-cola.com email if you don’t work at The Coca-Cola Company? I’d understand if it was an @gmail.com email though.
Parent
Unless you keep track of other social media artifacts (groups, pages, etc.), social media accounts usually fall under email addresses or directly under registrant names. The conditions for establishing parental relationships should pretty much be the same as the conditions for inheriting classification labels.
Acceptability
A method of determining acceptability may exist for some types of social media accounts. It’ll likely be computed using the Needleman–Wunsch algorithm again using the list of accepted registrant names and a Facebook/LinkedIn/Twitter account’s display name.
Post-Footprinting
The post-footprinting applications of social media accounts are similar to those of email addresses. They are to serve as phishing targets, and the usernames associated with them may be checked on sites like HaveIBeenPwned and PasteBin.
Inquisitor Workflow
Now that we got the fundamental concepts down, it’s time to put them all together in a single coherent process intended to (ideally) yield you the most comprehensive and accurate footprinting results possible.
Seeding the Intelligence Database
In the beginning, there was nothing; and as our homeboi, Parmenides, once pointed out:
ex nihilo nihil fit
Yeah. So basically, if the intelligence database is empty, you won’t really get anywhere as there’s really nothing to apply transforms or inferences to. Without transforms and inferences, you’re pretty much stuck because those are the only two types of automated information gathering mechanisms that Inquisitor is aware of.
Inquisitor can’t just guess which organization you’re targeting. You have to give it initial information. You have to give it “axioms” or “first truths” to go off from. You have to give it a clue on what sort of assets that your target organisation owns. This can be as simple as declaring that the site coca-cola.com belongs to your target organisation, or that the organisation that you’re targeting registers its domains and network blocks under the name The Coca-Cola Company, etc.
You should also look for a list of acquisitions and mergers performed by the company that you’re targeting in order to identify any other websites, or registrant names that you need to include in the seeding phase.
This initial information allows Inquisitor to know what kind of transformation methods to run, what classification labels can be inherited, etc.
Running Transforms
Now that we have some initial information from the seeding phase, we can start the process of actually discovering our target’s assets by probing various OSINT sources. This involves running the transformation methods of the asset objects that we provided during the seeding phase.
The mere assertion that coca-cola.com belongs to the target already gives Inquisitor plenty of information to go off from. From this alone, we can determine which OSINT sources we need to probe, what kind of questions we should be asking the source, and what constitutes asset ownership. For example, given that we know coca-cola.com belongs to our target, it may be a good idea to ask Google for domains that fall under coca-cola.com. After that, all domains found falling under coca-cola.com will be automatically classified as “accepted”.
Auditing and Verifying Transform Results
After transformation, you’d likely end up with a bunch of unclassified assets inside your intelligence database. These are the assets that Inquisitor has failed to automatically classify, and as such, you are going to have to perform manual classification on them yourself.
I know that going through a huge list of assets and classifying them one-by-one sounds like quite an ordeal, but there is a method to this, and it involves leveraging on the how the classification inheritance mechanism works.
I will explain in the following sections.
Verifying Registrant Names
You are going to want to manually inspect and classify registrant name objects first.
Aside from commonly being fewer in number than the rest of the asset types (hence, being less strenuous to classify), the classification inheritance function for most asset types point to the classification label of a registrant name. This means that by manually classifying a registrant name as “owned”, you would effectively be classifying all the domain names and network blocks registered under that name as “owned” as well. This effectively reduces the number of assets that we would need to manually review later on by a lot.
Generally, you’d want to take note of the following steps when reviewing registrant names. For the purpose of this section, let’s say we’re doing footprinting work for Coca-Cola.
Verify Promising Registrant Names
What’s that? You have an unclassified Registrant Name in your Intelligence Database labelled The Coca-Cola Company? Hmm. I wonder if this name is in any way related to your target company, which incidentally, is called “Coca-Cola”.
Yeah. You see, during the verification process, you’re going to have to engage in a variety of mentally laborious tasks such as determining whether the name The Coca-Cola Company actually refers to Coca-Cola.
If you think it does, then go ahead and classify that registrant name as “owned”.
However, aside from handling cases with blatantly obvious answers, there are some instances where a registrant name is indeed owned by the organization you’re doing footprinting for even though the name might look like it belongs to a different company such as in the case of registrant name Odwalla Inc..
In this case, the relationship with Coca-Cola isn’t very clear, but upon checking the list of acquisitions of Coca-Cola on Wikipedia, we can see that Odwalla was actually acquired by Coca-Cola in the past, hence, owned by it, meaning that it should fall under our scope as well.
So, yeah. When verifying registrant names, make sure to check if they were part of an acquisition or merger conducted by the company you’re doing footprinting for.
Reject Infrastructure Provider Registrant Names
After running transforms, you might end up with some registrant names belonging to various infrastructure providers such as Verisign or Amazon. This will occur because some of the IP addresses and domain names utilized by the websites of your target may fall under the network block of an IaaS provider and the domain of a TLD maintainer.
Make sure to reject these registrant names outright as they definitely have nothing to do with the organization you’re doing footprinting for, unless you’re actually doing footprinting for those organizations (which you shouldn’t be). Rejecting these registrant names removes them from the list of assets that you have yet to review, hence, allowing you to focus your attention on reviewing other unreviewed assets instead.
Verifying Domain Names
After you’re done manually inspecting and classifying registrant names, you’re going to want to look at manually inspecting and classifying domain names next.
I am well aware that network blocks usually come next in the de facto hierarchy of asset types. However, no other asset type inherits classification labels from network blocks as of the time this article was written, so we’re better off moving on to domain names for now as plenty of other asset types inherit their classification labels from them.
Generally, you’d want to take note of the following steps when reviewing domain names. For the purpose of this section, let’s say we’re doing footprinting work for Coca-Cola again.
Verify Promising Organization-Level Domain Names
Hmmm. Does the domain name coca-cola.com sound like it belongs to a company called Coca-Cola? Perhaps.
I know you hate having to manually classify assets, but in the end, Inquisitor just attempts to derive logical conclusions from the assumptions that you give it, so it can only minimize so much of your work. It can’t assume things for you, though I might build a feature like that sometime in the future.
Anyway, when manually inspecting and classifying domain names, you’d want to pay attention to organization-level domain names first.
What are organization-level domain names you ask? Well, kindly take a look the following list of domain names:
comcoca-cola.comᴡᴡᴡ.coca-cola.com
The first one (com) is what I’d call a registry-level domain name. Incidentally, it’s also a top-level domain name. By definition, these domain names belong to domain name registrars and domains for various organizations typically fall directly under them.
The difference between a registry-level domain name and a top-level domain name is that a top-level domain name does not have a parent domain while a registry-level domain name may have a parent in some instances. A lot of countries like the United Kingdom have their registry-level domains in the second-level (e.g. co.uk), therefore making my work here much, much harder.
Essentially, all top-level domain names are registry-level domain names, but not all registry-level domain names are top-level domain names. You can find a list of top-level domain names in this list maintained by IANA. Meanwhile, Mozilla keeps a list of registry-level domain names over here.
The next one (coca-cola.com) is what I’d call an organization-level domain name. By definition, these domain names are the domains registered by organizations to domain name registrars, and registrant organizations typically place their named assets (such as FTP and name servers) under domain names of this level.
We want to consider domains of this level first because by classifying them, we’d effectively be classifying the subdomains, hostnames, and email addresses under them as well, hence, saving us a lot of work later on.
The last one (ᴡᴡᴡ.coca-cola.com) is what I’d call a service-level domain name. By definition, these domain names address specific computing assets in the organization such as mail servers, name servers, file servers, web servers, or any other computing service provided by the organization over a network.
Domain names of this level typically fall under an organization-level domain name though the two levels are not mutually exclusive. Some organization-level domain names can address specific network services as well, hence, effectively becoming service-level domain names themselves.
Note that organizations may register multiple organization-level domain names for their organization so you’re not going to be looking for just one domain name to manually classify.
Reject Infrastructure Provider Domain Names
Just like in the case of ending up with infrastructure provider registrant names as discussed earlier, you’d likely end up with infrastructure provider domain names as well after running transformation functions. And just like what you did with infrastructure provider registrant names, you’d likely want to reject infrastructure provider domain names as well.
As of the time that this article was written, Inquisitor does not provide a mechanism for cascading rejection classification labels down to subdomains and other related assets, but the concept is currently in the road map for future developments. The best you could do for now is to create a rule which rejects all subdomains under a specific domain name.
(Not) Verifying IP Blocks and Email Addresses
After verifying registrant names and domain names, you’re probably thinking of verifying IP blocks and email addresses next. However, I’d recommend that this process be skipped altogether because aside from the fact that IP blocks and email addresses already inherit the classification labels of their corresponding parents, no other asset types inherit classification labels from either.
Additionally, it’s quite unlikely that you’d find a target-owned email address that falls under an un-owned domain, nor a target-owned IP block that is registered under an un-owned registrant name.
Verify Social Media Accounts
After verifying registrant names and domain names, you’d want to take a look at social media accounts next. Though no other asset type inherits their classification label from social media objects as of the time that this piece was written, they are directly part of your target organization’s attack surface so it would be wise to consider them as well.
You might be wondering why I’m asking you to manually verify social media objects but not IP blocks or email addresses. That’s because some social media objects may not exactly have a mechanism of inheriting classification labels from other assets, and thus, they need to be manually inspected.
Running Transforms Again (and Again)
After performing manual verification and classification of assets in the previous step, the model of your target organization (as represented by the contents of the intelligence database) will have effectively changed. New assets would probably have been added to the list of assets belonging to your target, hence, transforms that have never been executed before would be available for execution. These new transforms may potentially yield new assets that have not been discovered before.
Basically, you’d want to continue running transforms and performing manual verification over and over again until you encounter a phase where running transforms yield you no new assets. Once this happens, your footprinting process would essentially be over and it would be time for you to wrap up your results by generating reports.
Generating Reports
Inquisitor provides you a facility to export the contents of your intelligence database as well as generate a visualization of it. This will give you a map of your target’s public-facing assets in the later phases of penetration testing.
Leveraging OSINT Results
Now that you have a map of your target’s public-facing assets, it’s time you actually made use of the information contained within in order to assist you in the later phases of penetration testing.
Each asset can be leveraged in a different manner. For example, IP blocks can provide you a starting point for future ping sweeps and port scans, email addresses and social media accounts can provide you a starting point for future spear phishing attacks, domain names can provide you a starting point for finding vulnerable web applications, etc.
I’ve laid out the possible post-footprinting steps that you can take for each asset type in the “types of assets” section earlier in this article. You can refer to them once you’ve run out of ideas on what to do with your footprinting results.
Limitations
As of the time that this article was written, I have identified a couple of limitations that users need to watch out for in order to make sure that they get the best and most accurate results.
Wrong Assumptions, Wrong Results
The correctness of automatic classification results fundamentally lie with the truthfulness of the manual classifications you provide the system either through the seeding phase or the auditing and verification phase. That means, if you feed your intelligence database incorrect information, the system will inevitably generate incorrect results as well.
Bad With Certain Organization Types
As I mentioned a few times throughout this article, the Inquisitor footprinting approach doesn’t work well with the following organization types:
- PaaS/IaaS Providers
- Domain Name Registrars
The reasons why Inquisitor is particularly bad with these organization-types is because these organization types frequently defy classification inheritance assumptions, especially surrounding domain names.
For example, these organizations may delegate their subdomains to other entities, hence, breaking the assumption that all subdomains under an organization-owned domain is owned by that organization. Also, these organizations may resolve domain names for other organizations, hence, breaking the assumption that an organization owns a domain name if a DNS server under its control authoritatively resolves it.
Future Developments
For the future, I’d probably want to add more OSINT sources (e.g. Netcraft), track more asset types (e.g. documents and more social media accounts), and implement rules-based manual classification.